자료구조란 데이터를 정돈하여 저장한 구성체이다.
데이터에 편리하게, 빠르게, 효율적으로 접근, 탐색, 삽입, 삭제 등의 연산을 하기 위해 데이터를 조직하는 방법을 자료구조라고 일컫는다.
그러므로 자료구조를 설계할 때에는 데이터와 데이터에 관련된 연산들을 함께 고려하는 것이 필수적이다.
자료구조의 효율성
앞서 자료구조란 편리하고 빠르게, 효율적으로 연산을 하는 방법이라고 말했 듯이, 상황에 따라 선호되는 연산이 다르고, 각 연산마다 효율성 또한 다르다.
자료구조의 성능은 시간 복잡도와 공간 복잡도로 평가된다.
시간 복잡도는 단순히 연산의 수행 시간이라고 이해할 수 있다.
공간 복잡도는 알고리즘이 수행되는 동안 사용되는 메모리의 크기이다.
하지만 같은 문제 해결을 위한 자료구조 연산이라면 대부분 비슷한 크기의 메모리 공간을 사용
즉, 무시 가능한 차이의 공간 복잡도를 보이기 때문에 대부분의 경우 자료구조의 성능을 분석하기 위해
시간 복잡도만을 사용한다.
수행 시간
- 최악 경우 분석(Worst-case Analysis)
- 평균 경우 분석(Average-case Analysis)
- 최선 경우 분석(Best-case Analysis)
- 상각 분석(Amortized Analysis)
일반적으로 수행 시간은 최악 경우로 표현한다.
최악 경우로 분석할 경우 알고리즘이 수행될 때 ‘어떤 입력이 주어지더라도 수행 시간이 얼마 이상은 초과하지 않는다.’ 라는 상한의 의미를 갖기 때문이다.
자료구조의 종류
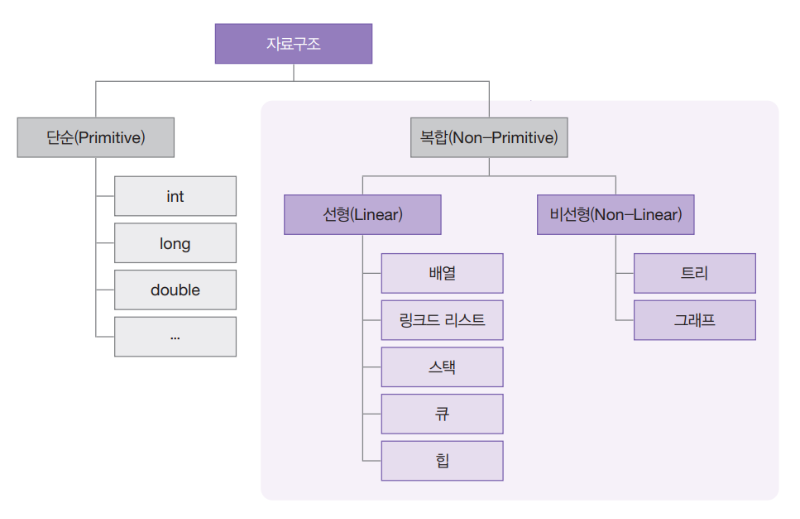
-
단순 데이터 구조
프로그래밍 언어에서 통상적으로 제공하는 기본 데이터 형식을 말한다.
-
복합 데이터 구조
-
선형 데이터 구조
데이터들이 순차적으로 나열되어 있는 구조이다. 각각의 데이터가 단 하나의 선행 데이터와 후행
데이터를 갖는다.
순차적인 접근으로 데이터에 접근하며, 일렬로 나열되는 데이터을 관리하는데 용이하다.
복잡한 관계를 표현하기에는 한계가 있는 경우가 많다.
배열, 연결 리스트, 스택, 큐, 힙이 선형적 자료 구조이다.
-
비선형 데이터 구조
데이터가 계층적이거나 네트워크 형태로 구성되어 있는 구조이다.
복잡하거나 계층적인 관계를 모델링할 때 용이하다.
트리와 그래프가 비선형적 자료 구조이다.
-
사진 출처 : 한빛+
]]>